包拯断案 | 集群备份续集:三招解决定时备份延迟@还故障一个真相
2024.04.11今天,小编给大家讲述自己亲身遇到的一个数据库集群备份问题,希望帮助DBA运维的你绕开这个烦恼,轻松找到答案!
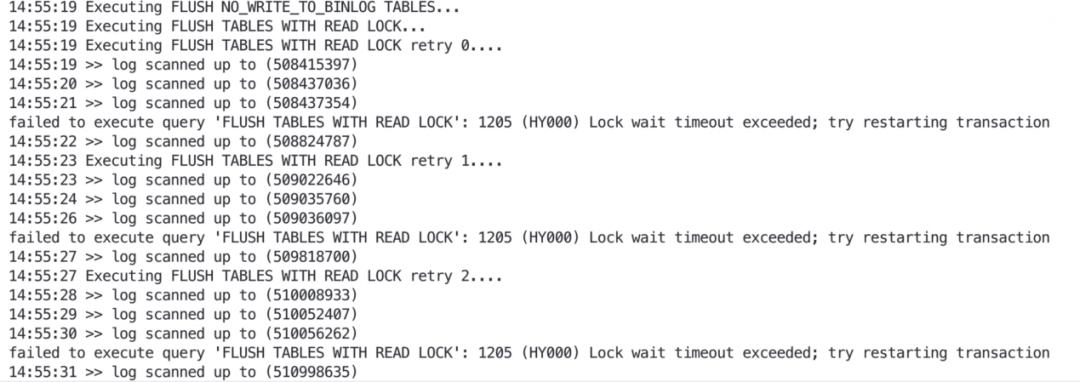
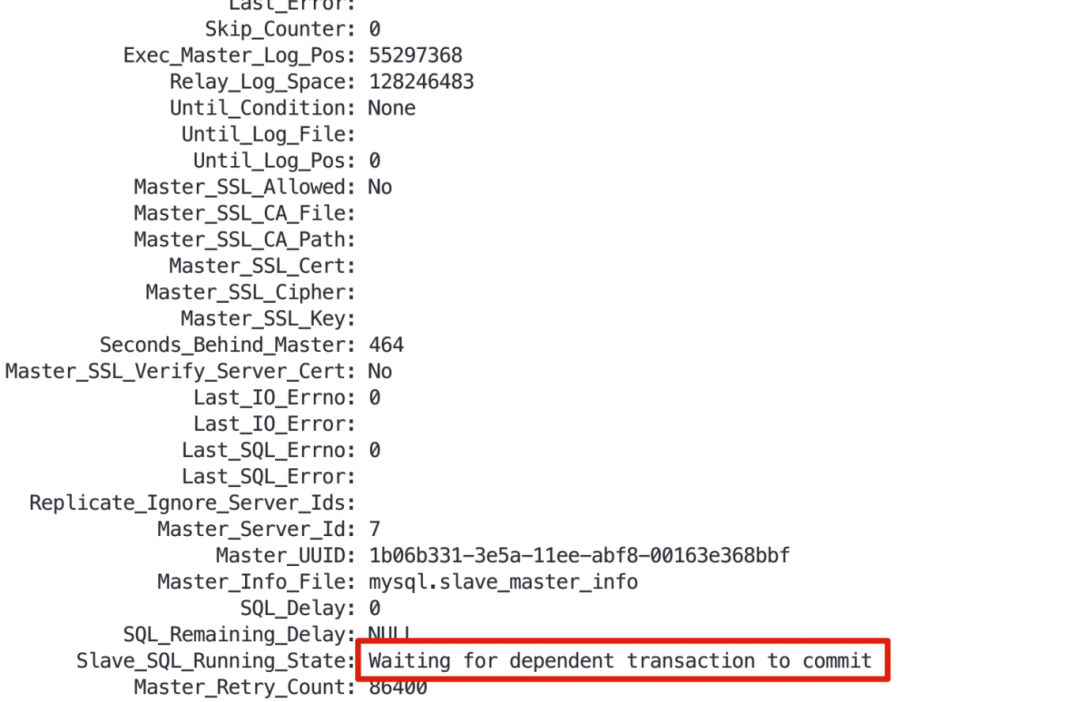
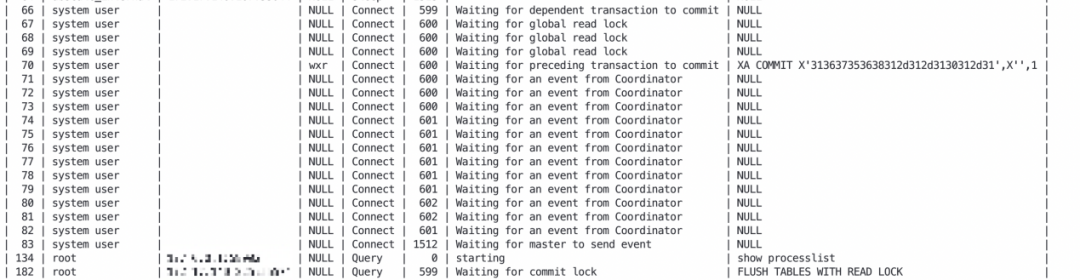
1、数据库集群在进行定时备份时(从节点备份),出现了主从延迟较大的告警,怎么破? 2、当出现告警时,你心里肯定在想:是不是从节点出现啥特殊故障了呢? 作为DBA的你,遇到问题无从下手,除了在问题面前徘徊,还能如何选择?如果你一次或多次遇到该问题还是无法解决,又很懊恼,该如何排忧呢?关注公众号,关注《包拯断案》专栏,让小编为你排忧解难~ 秘籍不能少,一整套故障排错及应对策略送给你,让你像包拯一样断案如神: #首先 遇到此类问题后,我们要做到心中有章(章程),遇事不慌。一定要冷静,仔细了解故障现象(与研发/用户仔细沟通其反馈的问题,了解故障现象、操作流程、数据库架构等信息) #其次 我们要根据故障现象进行初步分析。心中要想:从节点出现故障的原因到底是什么?是数据同步性能变慢了,还是遇到大事务了,或者是服务器存在故障影响了? #然后 针对上述思考,我们需要逐步验证并排除,确定问题排查方向。 #接着 确定了问题方向后,进行具体问题分析。通过现象得出部分结论,通过部分结论继续排查并论证。 #最后 针对问题有了具体分析后,再进行线下复现,最终梳理故障报告。 说了这么多理论,想必实战更让你心动。那我们就拿一个真实项目案例进行分析---某金融客户现场,运维人员在进行数据库集群定时备份(从节点备份)时,出现了主从延迟较大的告警,该如何快速分析处理。 1、故障发生场景 在客户现场兢兢业业进行项目运维的你,正在为某个数据库集群进行定时备份,却收到了主从延迟较大的告警,没法完成定时备份,不清楚是从节点、服务器或者其他哪个环节出了问题。 2、故障排查 遇到主从延迟告警,第一件事肯定是要排查主从状态。 通过show slave status\G看,IO和SQL线程都是YES,Exec_Master_Log_Pos值和gtid值无变化,看Slave_SQL_Running_State, 为Waiting for dependent transaction to commit状态。这时会想:是不是遇到啥并行复制死锁了。 通过show processlist 查看并行复制各个线程状态,就看到这一幕:备份的xtrabackup执行flush table with read lock与并行复制死锁了,卡在这了。 这咋办?得恢复呀~只能将备份执行的flush table with read lock语句 kill掉。 kill后主从同步恢复了,主从延迟也逐渐降低恢复到0了。 虽然指标暂时恢复正常了,但这个问题得仔细分析分析,之前没遇到过。 通过保留的show slave status结果和show processlist中的信息,解析对应的binlog并进行分析,尝试复现这种场景。 通过分析binlog,查询当前配置参数,确认了当前问题的触发逻辑。 简单描述下当前的配置和执行语句: flush table with read lock:这是一个老生常谈的语句,会关闭所有打开的表,并使用全局读锁锁定所有数据库的所有表。当前从节点配置了slave_preserve_commit_order=1,主节点执行的是xa事务。 slave_preserve_commit_order:这个参数主要控制并行复制中多线程之间的事务提交顺序是否和主节点一致。设置为1后,将保证提交顺序与主库一致。当有线程等待其他工作线程提交事务时,将会显示Waiting for preceding transaction to commit状态。 flush table with read lock 和并行复制触发死锁的逻辑如下: t1 xa start t2 flush table with read lock(waiting for slave work1) t3 xa start (waiting for backup session) t4 xa commit(waiting for preceding transaction to commit) 至此,我们就梳理出了整个事情的逻辑:从节点为了保证提交顺序与主库达成一致,多个sql线程之间就存在一定的依赖关系。flush table with read lock又在任意时刻都可能执行,对于xa事务来说,可能存在xa start与xa commit在binlog中相距很远的情况。若ftwrl在两个sql线程间隙执行,则可能存在session1需要等sessoin2提交,session2要等flush table with read lock释放锁,flush table with read lock 又在等session 1提交的情况。 绕了一大圈,把包大人都绕迷糊了,可能很多人也被绕蒙圈了。 知道问题原因了,我们来看看如何解决吧~ 在MySQL 5.7版本使用xtrabackup,是躲不掉flush table with read lock的。对于MySQL 8.0而言,有了clone功能,有lock instance for backup,并且xtrabackup在MySQL8.0对应版本中也做了优化;对于没有myisam表的,将不会执行flush table with read lock。 在MySQL5.7停服背景下遇到此问题,强烈推荐大家使用万里安全数据库GreatDB替换当前MySQL5.7版本,数据库不仅易用、稳定、高效,还能帮你一站式解决使用数据库使用过程中的疑难杂症。详情可点击文章底部“阅读原文”,查看万里数据库MySQL 5.7停服专区解决方案 如果暂时不能升级,可以先尝试试用GreatDB,我们在此给出优化方法。 参数名称 操作方法 safe-slave-backup 从节点备份时可以使用:在flush table with read lock前将sql线程停止,等待Slave_open_temp_tables为0后继续备份,完毕后再启动(这种方法不推荐,太粗暴了,sql线程异常告警同样会每晚折磨你) safe-slave-backup-timeout 与safe-slave-backup参数配合使用,等待Slave_open_temp_tables变为0的超时时间 ftwrl-wait-timeout 在执行flush table with read lock之前,如果被活跃会话阻塞了,就等待其执行完成;如果超时了活跃会话还没执行完,则会备份失败退出 ftwrl-wait-threshold 在执行flush table with read lock之前,如果有超过该设置时间的活跃会话,flush table with read lock会等待,直到超过ftwrl-wait-timeout,则会备份失败退出 backup-lock-timeout 设置锁等待超时时间默认为31536000,遇到锁等待会一直等待,减小锁等待时间,超时自动备份失败退出 在xtrabackup执行过程中,增加外部检测脚本,遇到flush table with read lock语句执行超过指定时间后,将语句kill并重新发起备份(数据量较少、备份速度快的可以使用,怕的是重复重试,超过预期备份窗口时间)。 修改xtrabackup代码,将flush table with read lock重试逻辑加入到其中(在此只演示将percona版本mysql中才能使用的backup超时和重试参数简单套用上,在flush table with read lock时进行超时重试,非专业版本,仅供参考) 下载percona xtrabackup代码 wget https://github.com/percona/percona-xtrabackup/archive/refs/tags/percona-xtrabackup-2.4.28.tar.gz 修改storage/innobase/xtrabackup/src/backup_mysql.cc中lock_tables_maybe函数 原代码如下 调整后代码如下 主要调整为:1148-117 之后进行源码编译,发起备份,测试一下修改后的逻辑是否可用。在备份命令中需额外添加两个参数,以控制超时时间和重试次数。(这两个参数在修改源码时也描述了,是直接套用的现有参数) --backup-lock-timeout=3 --backup-lock-retry-count=10 下图是加了重试后的备份日志截图,包大人看到后心中甚慰。 至此就完成了此次问题的全流程分析和处理。最后的“终极绝招”是一些小小尝试,仅供参考。在MySQL5.7停服的背景下,建议选择更易用、更稳定、更高效的数据库产品,才能为业务系统长久保驾护航。 1、flush table with read lock会获取全局读锁,在mysql并行复制的情况下,会出现与并行复制线程死锁的情况,生产上除备份外还是要尽量避免执行此语句。 2、备份对于数据库而言是重中之重,遇到问题时要仔细排查,梳理出触发问题的逻辑,才能更安全高效地做好每一次备份工作。01 心中有章,遇事不慌
02 真刀实战,我们能赢
time slave work1 backup session slave work2 03 故障处理
1143 if (have_galera_enabled) {1144 xb_mysql_query(connection,1145 "SET SESSION wsrep_causal_reads=0", false);1146 }11471148 xb_mysql_query(connection, "FLUSH TABLES WITH READ LOCK", false);11491150 if (opt_kill_long_queries_timeout) {1151 stop_query_killer();1152 }1143 if (have_galera_enabled) {1144 xb_mysql_query(connection,1145 "SET SESSION wsrep_causal_reads=0", false);1146 }11471148 if (retry_count>0) {1149 for (int i = 0; i <= retry_count; ++i) {1150 msg_ts("Executing FLUSH TABLES WITH READ LOCK retry %d....\n", i);1151 xb_mysql_query(connection, "FLUSH TABLES WITH READ LOCK", false, false);1152 uint err = mysql_errno(connection);1153 if (err == ER_LOCK_WAIT_TIMEOUT) {1154 os_thread_sleep(1000000);1155 continue;1156 }1157 if (err == 0) {1158 tables_locked = true;1159 }1160 break;11611162 }1163 if (!tables_locked) {1164 exit(EXIT_FAILURE);1165 }1166 return(true);1167 } else {1168 xb_mysql_query(connection, "FLUSH TABLES WITH READ LOCK", false);1169 }1170 /* xb_mysql_query(connection, "FLUSH TABLES WITH READ LOCK", false); */11711172 if (opt_kill_long_queries_timeout) {1173 stop_query_killer();1174 }